

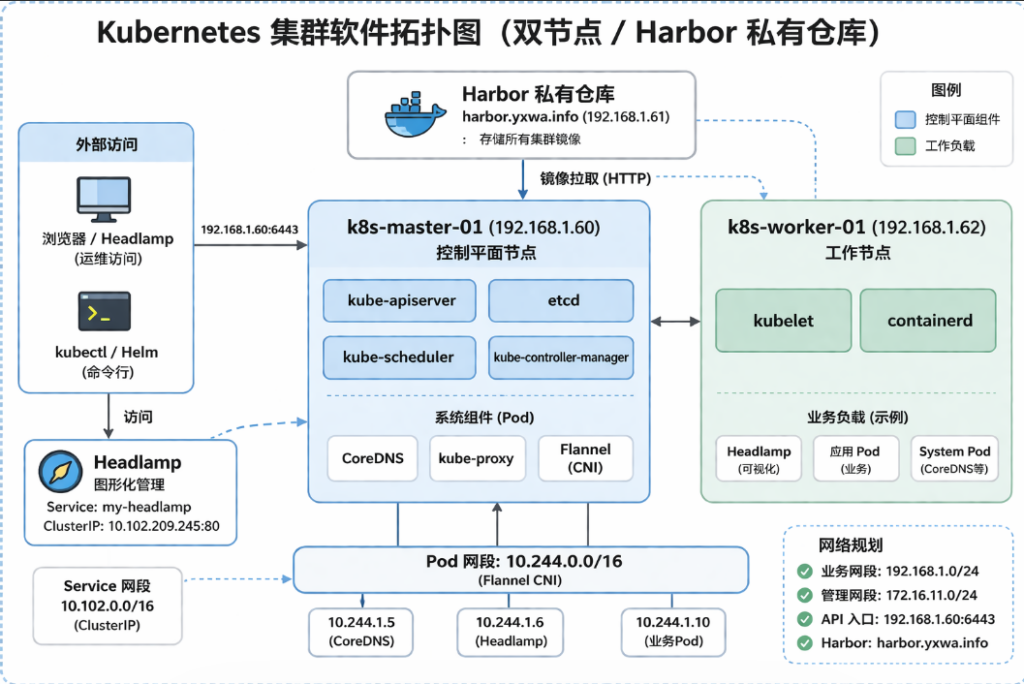
这次环境搭建Kubernetes,是在一套双网卡、双平面的内网环境里,把标准 kubeadm 集群弄到可用状态。
现网里,业务平面走 192.168.1.0/24
管理/外网走 172.16.11.0/24
控制平面节点为 k8s-master-01
业务 IP 是 192.168.1.60
工作节点为 k8s-worker-01
业务 IP 是 192.168.1.62
Harbor 单独部署在 192.168.1.61
并提前在 AD DNS 里解析了 harbor.yxwa.info,方便后面镜像地址、Ingress 域名和证书策略统一。内网环境里尽量不要让业务 YAML 长期依赖裸 IP,先用域名固定下来,后面切 HTTPS、做 HA 或者替换主机时,代价会小很多。
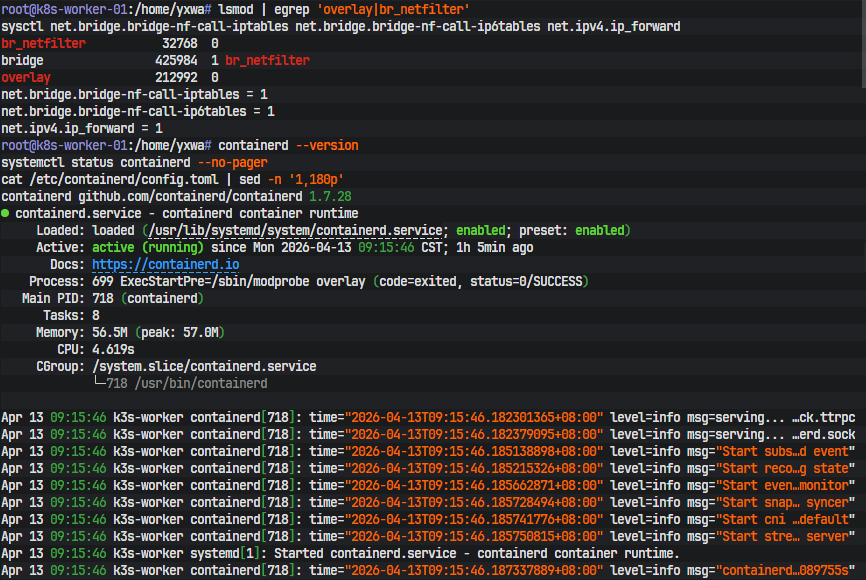
正式开始安装前,第一步先做的是节点侧内核准备。Kubernetes 不只是跑几个容器那么简单,它还要求 Linux 内核正确处理桥接流量和三层转发,否则网络插件即使装上去,Pod 通信也用不来。
所以先在 master 和 worker 上都写入模块加载配置,并加载 overlay 和 br_netfilter:
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
然后再把和桥接、转发相关的内核参数写进 sysctl:
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
sudo sysctl --system
这一步的意义不是照抄模板,而是显式告诉系统:经过 Linux bridge 的容器流量也要进 iptables,主机还要允许三层转发。前者是给后续的 Service、NAT 和网络策略打基础,后者则是让 Flannel 这类 CNI 插件能够正常接管 Pod 网段流量。执行完成后,可以用下面的命令确认结果:
lsmod | egrep 'overlay|br_netfilter'
sysctl net.bridge.bridge-nf-call-iptables net.bridge.bridge-nf-call-ip6tables net.ipv4.ip_forward

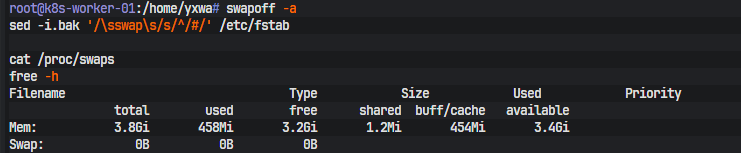
第二步处理的是 swap。kubeadm 对节点前置环境比较严格,swap 没关的话,初始化和加入集群阶段都容易出问题,所以这一步直接在每个节点上关闭并写回 /etc/fstab,避免重启后恢复:
sudo swapoff -a
sudo sed -i.bak '/\sswap\s/s/^/#/' /etc/fstab
cat /proc/swaps
free -h
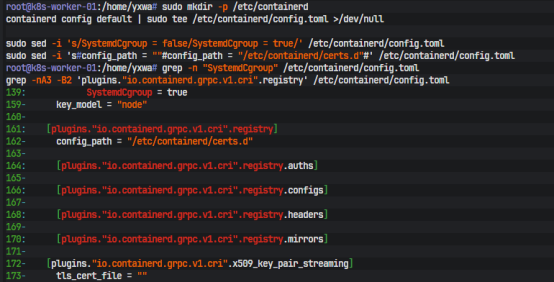
容器运行没有继续沿用 Docker 作为 Kubernetes runtime,而是直接使用 containerd。系统里虽然已经装了 containerd,但默认没有 /etc/containerd/config.toml,所以需要先导出默认配置,再手工改关键项。在 master 和 worker 上统一执行:
sudo mkdir -p /etc/containerd
containerd config default | sudo tee /etc/containerd/config.toml >/dev/null
接着把 cgroup 驱动改成 systemd,并启用 registry 配置目录:
sudo sed -i 's/SystemdCgroup = false/SystemdCgroup = true/' /etc/containerd/config.toml
sudo sed -i 's#config_path = ""#config_path = "/etc/containerd/certs.d"#' /etc/containerd/config.toml
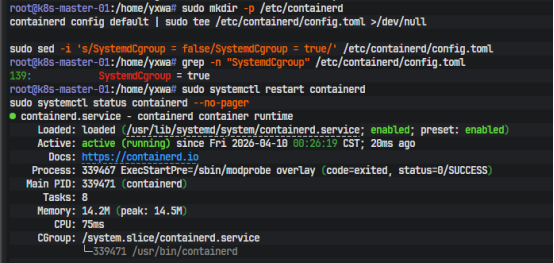
SystemdCgroup = true 是为了让 kubelet 和 runtime 的 cgroup 驱动一致,避免资源控制和进程层级混乱;config_path 则决定了 containerd 会不会真正读取你后面写进去的 hosts.toml。如果这里还是空的,私有仓库配置哪怕写对了,CRI 也不会生效。改完后重启 runtime:
sudo systemctl restart containerd
sudo systemctl status containerd --no-pager
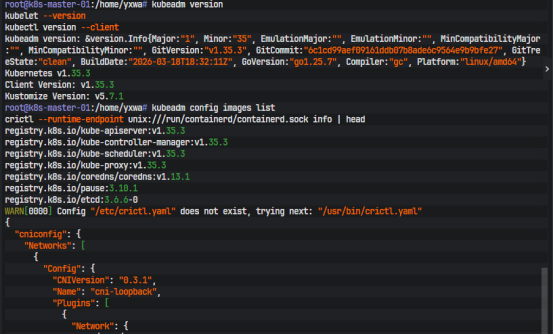
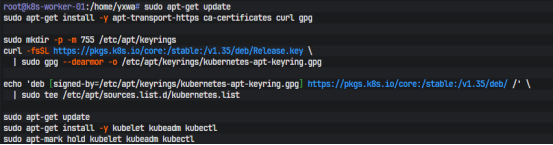
kubeadm、kubelet 和 kubectl 的安装没有再用旧的 apt.kubernetes.io 仓库,而是直接走当前官方推荐的 pkgs.k8s.io,版本固定在 v1.35 分支上。由于默认的镜像源没有k8S的组件,所以我们先加入阿里云的源
echo "deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.30/deb/ /" | sudo tee /etc/apt/sources.list.d/kubernetes.list
master 和 worker 都执行同一套命令:
sudo apt-get update
sudo apt-get install -y apt-transport-https ca-certificates curl gpgsudo
mkdir -p -m 755 /etc/apt/keyrings
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.35/deb/Release.key \
| sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpgecho 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.35/deb/ /' \
| sudo tee /etc/apt/sources.list.d/kubernetes.listsudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
sudo apt-mark hold kubelet kubeadm kubectl
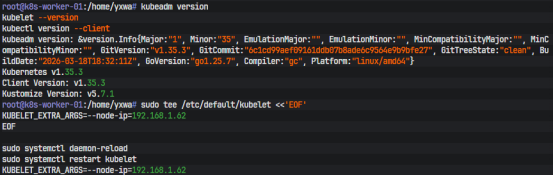
安装完成后,用下面的命令确认版本:
kubeadm version
kubelet --version
kubectl version --client
这里做 apt-mark hold 的目的,是避免系统后面自动升级把控制面和节点组件版本打乱。基础集群刚搭好的阶段,稳定比追新更重要。
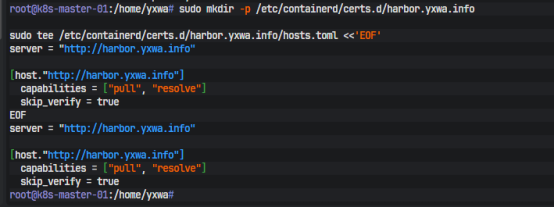
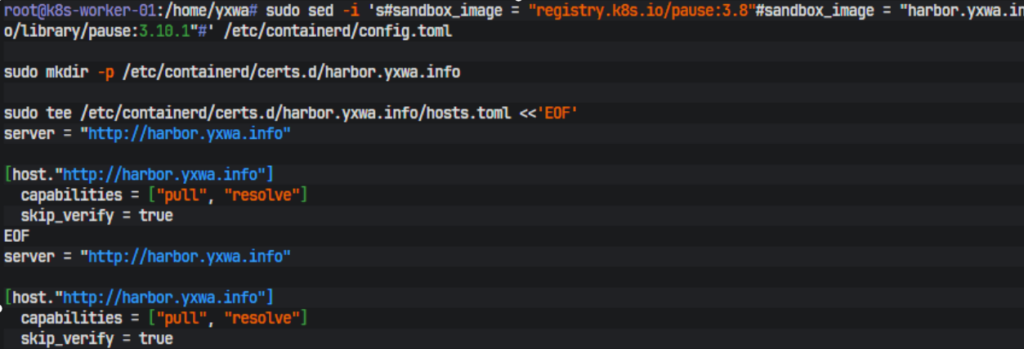
这套环境真正的难点其实不在 kubeadm 本身,而在镜像来源。节点虽然能访问部分公网入口,但实际拉 registry.k8s.io 和 ghcr.io 后端资源时经常超时,所以最终没有再让 kubeadm 直连公网,而是把核心镜像全部先同步进 Harbor,再由集群统一从内网私仓拉取。Harbor 已经提前跑通,仓库地址固定为 harbor.yxwa.info。为了让 containerd 知道这是一个 HTTP 仓库,需要在节点上单独写 hosts.toml:
sudo mkdir -p /etc/containerd/certs.d/harbor.yxwa.infosudo tee /etc/containerd/certs.d/harbor.yxwa.info/hosts.toml <<'EOF'
server = "http://harbor.yxwa.info"[host."http://harbor.yxwa.info"]
capabilities = ["pull", "resolve"]
skip_verify = true
EOF
同时把 sandbox 镜像也显式切到 Harbor 中的 pause:
sudo sed -i 's#sandbox_image = "registry.k8s.io/pause:3.8"#sandbox_image = "harbor.yxwa.info/library/pause:3.10.1"#' /etc/containerd/config.toml
sudo systemctl restart containerd
这一步的含义很直接:CRI 默认会把远端仓库按 HTTPS 处理,而当前 Harbor 是 HTTP 部署,如果不明确写协议,它会一直去尝试 443,最后表现成各种 connection refused 或 timeout。把 sandbox_image 一并改掉,则是为了让 pause 镜像也走内网仓库,避免节点在启动 Pod 时偷偷再去请求公网。

控制平面初始化时,核心镜像已经预先同步到了 Harbor,因此 kubeadm init 直接显式指定了业务网 IP、Pod 网段和镜像仓库:
sudo kubeadm init \
--apiserver-advertise-address=192.168.1.60 \
--pod-network-cidr=10.244.0.0/16 \
--node-name=k8s-master-01 \
--image-repository=harbor.yxwa.info/library
这里每个参数都不是可有可无。--apiserver-advertise-address=192.168.1.60 是为了强制 API Server 使用业务网地址,而不是管理网卡;
--pod-network-cidr=10.244.0.0/16 则是提前和 Flannel 的默认网段保持一致;
--image-repository 让 kubeadm 初始化过程中所有控制面镜像都直接从 Harbor 获取,彻底绕开了外部仓库不稳定的问题。
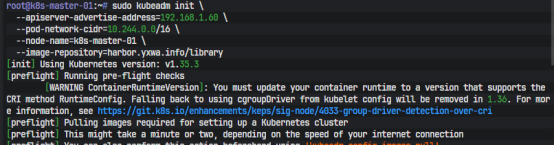
初始化成功后,按标准方式导出 kubeconfig:
export KUBECONFIG=/etc/kubernetes/admin.conf
kubectl get nodes -o wide
kubectl get pods -A
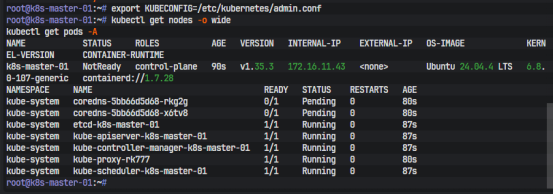
刚初始化完时,CoreDNS 处于 Pending、节点显示 NotReady 是正常现象,因为这时还没有装 CNI。
双网卡环境还有一个细节必须处理,就是 kubelet 默认上报的节点 IP 往往会选错。为了让 master 和 worker 都固定使用业务网地址,需要在 /etc/default/kubelet 里增加 --node-ip。master 节点写法如下:
sudo tee /etc/default/kubelet <<'EOF'
KUBELET_EXTRA_ARGS=--node-ip=192.168.1.60
EOF
sudo systemctl daemon-reload
sudo systemctl restart kubelet
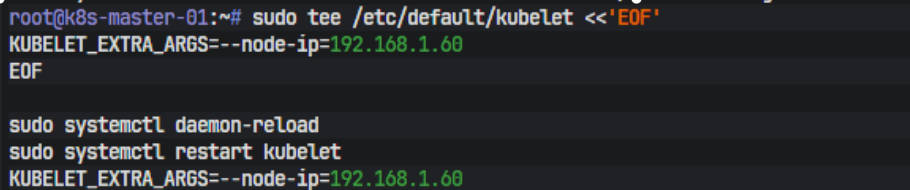
worker 节点则改成 192.168.1.62
这一步的意义是把节点身份绑定到业务平面。否则集群虽然能跑,但节点内部地址会落到 172.16.11.x 那张管理网卡上。
CNI 这里最终用了 Flannel。不是因为它功能最强,而是当前阶段目标很明确:先把集群底座跑通,再往上叠业务。Flannel 够轻,和 10.244.0.0/16 也天然匹配。先应用官方清单:
kubectl apply -f https://github.com/flannel-io/flannel/releases/latest/download/kube-flannel.yml

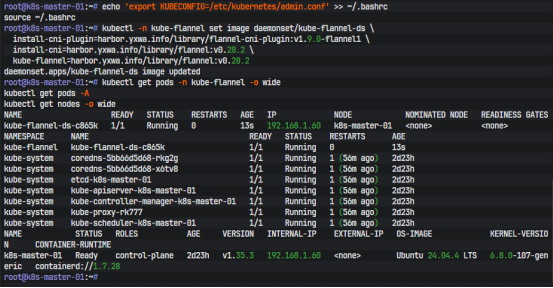
但由于默认镜像来自 ghcr.io,实际部署时依旧会遇到镜像拉取不稳定的问题。所以最终还是把 flannel 和 flannel-cni-plugin 镜像同步进 Harbor,然后直接把 DaemonSet 镜像源切到内网仓库:
kubectl -n kube-flannel set image daemonset/kube-flannel-ds \
install-cni-plugin=harbor.yxwa.info/library/flannel-cni-plugin:v1.9.0-flannel1 \
install-cni=harbor.yxwa.info/library/flannel:v0.28.2 \
kube-flannel=harbor.yxwa.info/library/flannel:v0.28.2
随后就可以观察网络插件和节点状态:
kubectl get pods -n kube-flannel -o wide
kubectl get pods -A
kubectl get nodes -o wide
当 kube-flannel 变成 Running,CoreDNS 也会从 Pending 恢复成 Running,节点状态同步转成 Ready。这说明集群网络已经真正接管成功。
工作节点的加入逻辑和控制平面保持一致:先做 swap,最后执行加入命令。
镜像源修改到自己的harbor,以及访问harbor时使用http
内核模块
containerd 部分
再装 kubeadm 套件
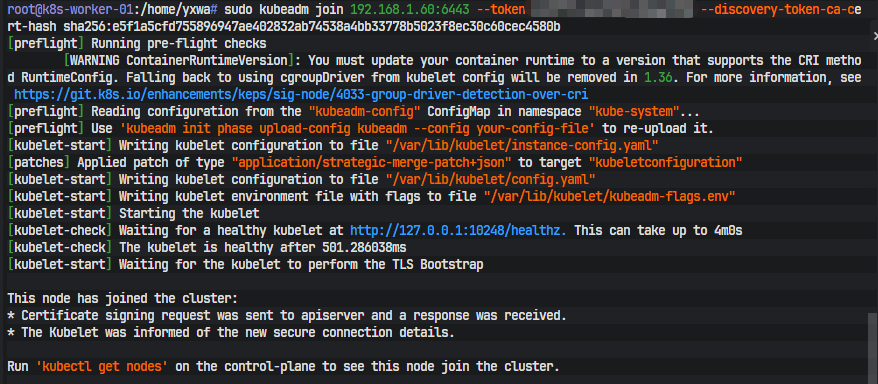
新的 join 命令建议直接在 master 上生成:
export KUBECONFIG=/etc/kubernetes/admin.conf
kubeadm token create --print-join-command
然后在 worker 上执行输出的 join 命令,例如:
sudo kubeadm join 192.168.1.60:6443 \
--token <token> \
--discovery-token-ca-cert-hash sha256:<hash>
加入完成后,回到 master 检查节点状态:
kubectl get nodes -o wide
看到 k8s-master-01 和 k8s-worker-01 同时为 Ready,并且内部地址都是 192.168.1.x,就说明双节点集群已经正式成型。

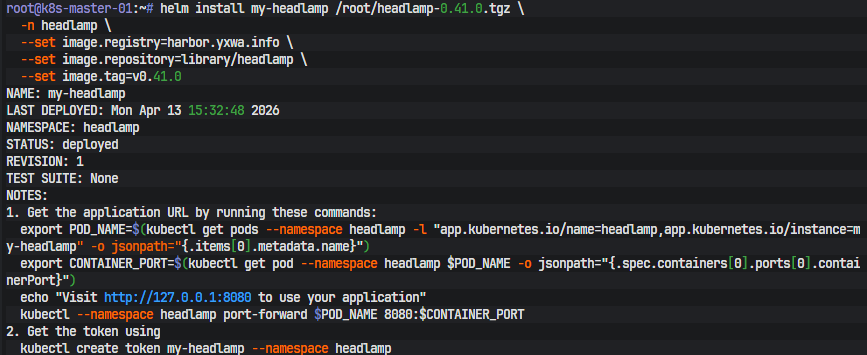
在底座搭好之后,我又顺手部署了一个轻量的图形化入口 Headlamp。它的意义并不是替代 kubectl,而是给后面查看节点、Pod、事件和日志提供一个 Web 界面。由于在线安装 chart 和镜像都受外部网络影响,最终还是走了相同的处理路径:先在外部环境拉取 headlamp-0.41.0.tgz 和镜像,再同步进 Harbor,最后在集群里使用本地 chart 包安装,并把镜像源改成 Harbor。安装命令如下:
kubectl create namespace headlamphelm install my-headlamp /root/headlamp-0.41.0.tgz \
-n headlamp \
--set image.registry=harbor.yxwa.info \
--set image.repository=library/headlamp \
--set image.tag=v0.41.0
部署完成后查看状态:
kubectl get pods -n headlamp -o wide
kubectl get svc -n headlamp
kubectl create token my-headlamp -n headlamp
如果 Headlamp Pod 正常跑在 worker 上,说明 Helm、本地 chart、Harbor 镜像和集群业务负载这条链路也已经打通。

登陆图形headlamp界面化只需要输入token即可

这次环境搭建真正有价值的地方在于把双网卡选路、containerd 配置、Harbor 私仓、控制面镜像、Flannel 网络插件和节点加入流程全部串成了一条闭环。等镜像入口稳定下来,后续无论是 Gitea、Ingress Controller、TLS、NFS CSI、Longhorn 还是 Argo CD,本质上都只是继续沿着同一条内网路径扩展。
对当前阶段来说,这套 kubeadm 双节点集群已经具备了继续往上承载业务的基础。前端可以继续接 HAProxy 和 Keepalived 做统一入口,集群内部可以加 Ingress 和 TLS,存储层可以接 NFS CSI 或 Longhorn,而代码托管与持续交付则可以继续围绕 Gitea、Harbor 和 Argo CD 展开。底座一旦扎稳,后面的每一步就不再是重搭环境,而是在既有平台上继续叠加能力。
Comments NOTHING